

Inspirados em grandes modelos de linguagem, os pesquisadores desenvolvem uma técnica de treinamento que reúne diversos dados para ensinar novas habilidades aos robôs.
No clássico desenho animado “Os Jetsons”, Rosie, a empregada robótica, alterna perfeitamente entre aspirar a casa, preparar o jantar e levar o lixo para fora. Mas na vida real, treinar um robô de uso geral continua a ser um grande desafio.
Normalmente, os engenheiros coletam dados específicos de um determinado robô e tarefa, que usam para treinar o robô em um ambiente controlado. No entanto, a recolha destes dados é dispendiosa e demorada, e o robô provavelmente terá dificuldades para se adaptar a ambientes ou tarefas que nunca viu antes.
Para treinar melhores robôs de uso geral, os pesquisadores do MIT desenvolveram uma técnica versátil que combina uma enorme quantidade de dados heterogêneos de muitas fontes em um sistema que pode ensinar a qualquer robô uma ampla gama de tarefas.
Seu método envolve o alinhamento de dados de domínios variados, como simulações e robôs reais, e múltiplas modalidades, incluindo sensores de visão e codificadores de posição de braço robótico, em uma “linguagem” compartilhada que um modelo generativo de IA pode processar.
Ao combinar uma enorme quantidade de dados, esta abordagem pode ser usada para treinar um robô para executar uma variedade de tarefas sem a necessidade de começar a treiná-lo do zero todas as vezes.
Este método pode ser mais rápido e menos dispendioso do que as técnicas tradicionais porque requer muito menos dados específicos da tarefa. Além disso, superou o treinamento desde o início em mais de 20% em simulação e experimentos do mundo real.
“Na robótica, as pessoas muitas vezes afirmam que não temos dados de treinamento suficientes. Mas, na minha opinião, outro grande problema é que os dados vêm de muitos domínios, modalidades e hardware robótico diferentes. Nosso trabalho mostra como você seria capaz de treinar um robô com todos eles juntos”, diz Lirui Wang, estudante de graduação em engenharia elétrica e ciência da computação (EECS) e autor principal de um artigo sobre essa técnica.
Os co-autores de Wang incluem Jialiang Zhao, estudante de pós-graduação do EECS; Xinlei Chen, cientista pesquisador da Meta; e o autor sênior Kaiming He, professor associado do EECS e membro do Laboratório de Ciência da Computação e Inteligência Artificial (CSAIL). A pesquisa será apresentada na Conferência sobre Sistemas de Processamento de Informação Neural.
Inspirado em LLMs
Uma “política” robótica leva em conta observações de sensores, como imagens de câmeras ou medições proprioceptivas que rastreiam a velocidade e a posição de um braço robótico, e então informam ao robô como e onde se mover.
As políticas são normalmente treinadas usando aprendizagem por imitação, o que significa que um ser humano demonstra ações ou teleopera um robô para gerar dados, que são alimentados em um modelo de IA que aprende a política. Como esse método usa uma pequena quantidade de dados específicos de tarefas, os robôs geralmente falham quando seu ambiente ou tarefa muda.
Para desenvolver uma abordagem melhor, Wang e seus colaboradores inspiraram-se em grandes modelos de linguagem como o GPT-4.
Esses modelos são pré-treinados usando uma enorme quantidade de dados de linguagem diversificada e, em seguida, ajustados, alimentando-os com uma pequena quantidade de dados específicos da tarefa. O pré-treinamento com tantos dados ajuda os modelos a se adaptarem para um bom desempenho em uma variedade de tarefas.
“No domínio da linguagem, os dados são apenas frases. Na robótica, dada toda a heterogeneidade dos dados, se quisermos pré-treinar de maneira semelhante, precisamos de uma arquitetura diferente”, diz ele.
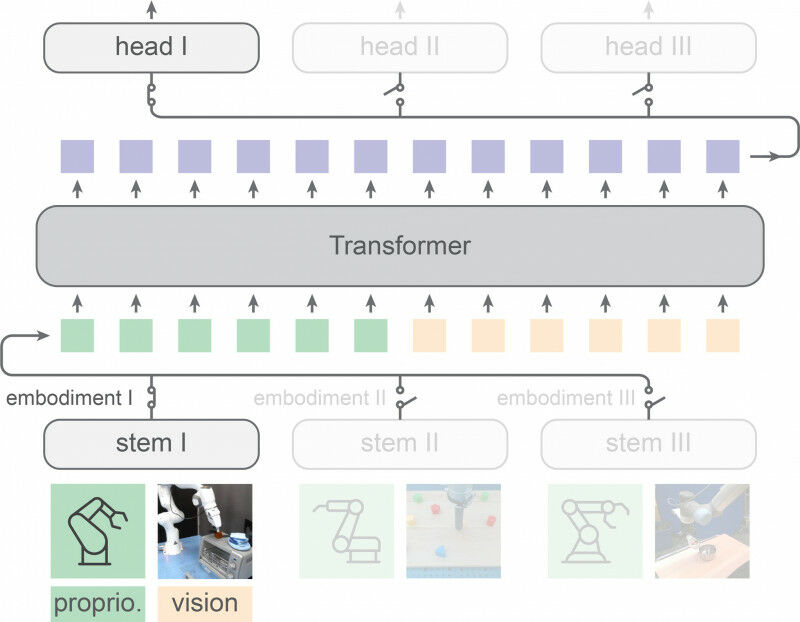
Os dados robóticos assumem muitas formas, desde imagens de câmeras até instruções de linguagem e mapas de profundidade. Ao mesmo tempo, cada robô é mecanicamente único, com número e orientação diferentes de braços, garras e sensores. Além disso, os ambientes onde os dados são coletados variam amplamente.
Os pesquisadores do MIT desenvolveram uma nova arquitetura chamada Transformadores Pré-treinados Heterogêneos (HPT) que unifica dados dessas diversas modalidades e domínios.
Eles colocaram um modelo de aprendizado de máquina conhecido como transformador no meio de sua arquitetura, que processa informações de visão e propriocepção. Um transformador é o mesmo tipo de modelo que forma a espinha dorsal de grandes modelos de linguagem.
Os pesquisadores alinham os dados da visão e da propriocepção no mesmo tipo de entrada, chamado token, que o transformador pode processar. Cada entrada é representada com o mesmo número fixo de tokens.
Em seguida, o transformador mapeia todas as entradas em um espaço compartilhado, transformando-se em um enorme modelo pré-treinado à medida que processa e aprende com mais dados. Quanto maior for o transformador, melhor será o seu desempenho.
Um usuário só precisa fornecer ao HPT uma pequena quantidade de dados sobre o design, a configuração e a tarefa que deseja que seu robô execute. Em seguida, o HPT transfere o conhecimento que o transformador adquiriu durante o pré-treinamento para aprender a nova tarefa.
Habilitando movimentos hábeis
Um dos maiores desafios do desenvolvimento do HPT foi construir um enorme conjunto de dados para pré-treinar o transformador, que incluía 52 conjuntos de dados com mais de 200.000 trajetórias de robôs em quatro categorias, incluindo vídeos de demonstração humana e simulação.
Os pesquisadores também precisavam desenvolver uma maneira eficiente de transformar sinais brutos de propriocepção de uma série de sensores em dados que o transformador pudesse manipular.
“A propriocepção é fundamental para permitir muitos movimentos hábeis. Como o número de tokens em nossa arquitetura é sempre o mesmo, damos a mesma importância à propriocepção e à visão”, explica Wang.
Quando testaram o HPT, ele melhorou o desempenho do robô em mais de 20% em simulações e tarefas do mundo real, em comparação com o treinamento desde o início. Mesmo quando a tarefa era muito diferente dos dados de pré-treinamento, o HPT ainda melhorou o desempenho.
“Este artigo fornece uma nova abordagem para treinar uma única política em várias modalidades de robôs. Isso permite o treinamento em diversos conjuntos de dados, permitindo que os métodos de aprendizagem de robôs aumentem significativamente o tamanho dos conjuntos de dados nos quais eles podem treinar. Também permite que o modelo se adapte rapidamente a novas incorporações de robôs, o que é importante porque novos projetos de robôs são continuamente produzidos”, diz David Held, professor associado do Instituto de Robótica da Universidade Carnegie Mellon, que não esteve envolvido neste trabalho.
No futuro, os pesquisadores querem estudar como a diversidade de dados poderia impulsionar o desempenho do HPT. Eles também querem aprimorar o HPT para que ele possa processar dados não rotulados, como GPT-4 e outros modelos de linguagem de grande porte.
“Nosso sonho é ter um cérebro robótico universal que você possa baixar e usar em seu robô sem nenhum treinamento. Embora estejamos apenas nos estágios iniciais, continuaremos nos esforçando e esperamos que o dimensionamento leve a um avanço na robótica políticas, como aconteceu com grandes modelos de linguagem”, diz ele.



{kind=link}